sentarget¶
SenTarget provides already set-up PyTorch models for targeted sentiment analysis a.k.a. Aspact Based Sentiment Analysis (ASBA).
Here is some examples on how to use this package:
# PyTorch
import torchtext
from torchtext.vocab import Vectors
import torch.nn as nn
import torch.optim as optim
# SenTarget
from sentarger.datasets import NoReCfine
from sentarget.nn.models.lstm import BiLSTM
# Extract the fields from the dataset (conll format).
# Here we are only interested on the text and labels.
TEXT = torchtext.data.Field(lower=False, include_lengths=True, batch_first=True)
LABEL = torchtext.data.Field(batch_first=True)
FIELDS = [("text", TEXT), ("label", LABEL)]
train_data, eval_data, test_data = NoReCfine.splits(FIELDS)
# Defines the vocabulary to work on, and add already pre-trained word embeddings.
# NOTE: these word embeddings are not part of the repository, but can be downloaded from nlpl servers (58.zip file).
VOCAB_SIZE = 1_200_000
VECTORS = Vectors(name='word2vec/model.txt')
TEXT.build_vocab(train_data,
max_size = VOCAB_SIZE,
vectors = VECTORS,
unk_init = torch.Tensor.normal_)
LABEL.build_vocab(train_data)
# Build the iterators, and set it to the 'cpu'
BATCH_SIZE = 64
device = torch.device('cpu')
train_iterator, eval_iterator, test_iterator = data.BucketIterator.splits(
(train_data, eval_data, test_data),
batch_size = BATCH_SIZE,
sort_within_batch = True,
device = device)
# Load the model
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 128
OUTPUT_DIM = len(LABEL.vocab)
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.25
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = BiLSTM(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
# Initialize the embedding layers with the pre-trained word embeddings (previously loaded)
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
pretrained_embeddings = TEXT.vocab.vectors
model.init_embeddings(pretrained_embeddings, ignore_index=[PAD_IDX, UNK_IDX])
# ...and fit / train the model
# NOTE: there are two ways to train a model.
# Either you can use the `tensorflow` *API*, with the `.fit()` method.
# In that case, you should make sure that all methods are defined within the network you loaded.
# The other way uses the `PyTorch` *API* with a `Solver` to train a specific model.
# Both methods are similar, just the *API* changes.
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# Train the model for 50 epochs
EPOCHS = 50
model.fit(EPOCHS, train_iterator, eval_iterator, criterion, optimizer)
sentarget.nn¶
sentarget.nn.solver¶
A Solver is an object used for training, evaluating and testing a model.
The performance is stored in a dictionary, both for training and testing.
In addition, the best model occurred during training is stored,
as well as it’s checkpoint to re-load a model at a specific epoch.
Example:
import torch.nn as nn
import torch.optim as optim
model = nn.Sequential(nn.Linear(10, 100), nn.Sigmoid(), nn.Linear(100, 5), nn.ReLU())
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss(ignore_index = LABEL_PAD_IDX)
solver = BiLSTMSolver(model, optimizer=optimizer, criterion=criterion)
# epochs = number of training loops
# train_iterator = Iterator, DataLoader... Training data
# eval_iterator = Iterator, DataLoader... Eval data
solver.fit(train_iterator, eval_iterator, epochs=epochs)
-
class
sentarget.nn.solver.Solver(model, criterion=None, optimizer=None)[source]¶ Train and evaluate model.
model(Module): model to optimize or test.checkpoint(dict): checkpoint of the best model tested.criterion(Loss): loss function.optimizer(Optimizer): optimizer for weights and biases.performance(dict): dictionary where performances are stored.'train'(dict): training dictionary.'eval'(dict): testing dictionary.
- Parameters
model (Module) – model to optimize or test.
criterion (Loss) – loss function.
optimizer (Optimizer) – optimizer for weights and biases.
-
abstract
evaluate(iterator, *args, **kwargs)[source]¶ Evaluate one time the model on iterator data.
- Parameters
iterator (Iterator) – iterator containing batch samples of data.
- Returns
the performance and metrics of the training session.
- Return type
dict
-
fit(train_iterator, eval_iterator, *args, epochs=10, **kwargs)[source]¶ Train and evaluate a model X times. During the training, both training and evaluation results are saved under the performance attribute.
- Parameters
train_iterator (Iterator) – iterator containing batch samples of data.
eval_iterator (Iterator) – iterator containing batch samples of data.
epochs (int) – number of times the model will be trained.
verbose (bool, optional) – if
Truedisplay a progress bar and metrics at each epoch. The default isTrue.
Examples:
>>> solver = MySolver(model, criterion=criterion, optimizer=optimizer) >>> # Train & eval EPOCHS times >>> EPOCHS = 10 >>> solver.fit(train_iterator, eval_iterator, epochs=EPOCHS, verbose=True) Epoch: 1/10 Training: 100% | [==================================================] Evaluation: 100% | [==================================================] Stats Training: | Loss: 0.349 | Acc: 84.33% | Prec.: 84.26% Stats Evaluation: | Loss: 0.627 | Acc: 72.04% | Prec.: 72.22% >>> # ...
-
get_accuracy(y_tilde, y)[source]¶ Compute accuracy from predicted classes and gold labels.
- Parameters
y_tilde (Tensor) – 1D tensor containing the predicted classes for each predictions in the batch. This tensor should be computed through get_predicted_classes(y_hat) method.
y (Tensor) – gold labels. Note that y_tilde an y must have the same shape.
- Returns
the mean of correct answers.
- Return type
float
Examples:
>>> y = torch.tensor([0, 1, 4, 2, 1, 3, 2, 1, 1, 3]) >>> y_tilde = torch.tensor([0, 1, 2, 2, 1, 3, 2, 4, 4, 3]) >>> solver.get_accuracy(y_tilde, y) 0.7
-
save(filename=None, dirpath='.', checkpoint=True)[source]¶ Save the best torch model.
- Parameters
filename (str, optional) – name of the model. The default is “model.pt”.
dirpath (str, optional) – path to the desired foldre location. The default is “.”.
checkpoint (bool, optional) –
Trueto save the model at the best checkpoint during training.
sentarget.nn.models¶
sentarget.nn.models.model¶
Defines a model template. A Model is really similar to the Module class, except that a Model has more inner methods, used to train, evaluate and test a neural network.
The API is similar to sklearn or tensorflow.
class Net(Model):
def __init__(self, *args):
super(Model, self).__init__()
# initialize your module as usual
def forward(*args):
# one forward step
pass
def run(train_iterator, criterion, optimizer):
# train one single time the network
pass
def evaluate(eval_iterator, criterion):
# evaluate one single time the network
pass
def predict(test_iterator):
# predict one single time the network
pass
# Run and train the model
model = Net()
model.fit(epochs, train_iterator, eval_iterator, criterion, optimizer)
-
class
sentarget.nn.models.model.Model[source]¶ A Model is used to define a neural network. This template is easier to handle for hyperparameters optimization, as the
fit,train,evaluatemethods are part of the model.checkpoint(dict): checkpoint of the best model tested.criterion(Loss): loss function.optimizer(Optimizer): optimizer for weights and biases.performance(dict): dictionary where performances are stored.'train'(dict): training dictionary.'eval'(dict): testing dictionary.
-
describe_performance(*args, **kwargs)[source]¶ Get a display of the last performance for both train and eval.
- Returns
two strings showing statistics for train and eval sessions.
- Return type
tuple
-
abstract
evaluate(iterator, criterion, optimizer, *args, **kwargs)[source]¶ Evaluate one time the model on iterator data.
- Parameters
iterator (Iterator) – iterator containing batch samples of data.
criterion (Loss) – loss function to measure scores.
optimizer (Optimizer) – optimizer used during training to update weights.
- Returns
the performance and metrics of the training session.
- Return type
dict
-
fit(train_iterator, eval_iterator, criterion=None, optimizer=None, epochs=10, verbose=True, compare_on='accuracy', **kwargs)[source]¶ Train and evaluate a model X times. During the training, both training and evaluation results are saved under the performance attribute.
- Parameters
train_iterator (Iterator) – iterator containing batch samples of data.
eval_iterator (Iterator) – iterator containing batch samples of data.
epochs (int) – number of times the model will be trained.
criterion (Loss) – loss function to measure scores.
optimizer (Optimizer) – optimizer used during training to update weights.
verbose (bool, optional) – if
Truedisplay a progress bar and metrics at each epoch.compare_on (string) – name of the score on which models are compared.
- Returns
the best model evaluated.
- Return type
Examples:
>>> model = MyModel() >>> # Train & eval EPOCHS times >>> criterion = nn.CrossEntropyLoss() >>> optimizer = metrics.Adam(model.parameters()) >>> EPOCHS = 10 >>> model.fit(train_iterator, eval_iterator, epochs=EPOCHS, criterion=criterion, optimizer=optimizer) Epoch: 1/10 Training: 100% | [==================================================] Evaluation: 100% | [==================================================] Stats Training: | Loss: 0.349 | Acc: 84.33% | Prec.: 84.26% Stats Evaluation: | Loss: 0.627 | Acc: 72.04% | Prec.: 72.22% >>> # ...
-
predict(iterator, *args, **kwargs)[source]¶ Predict the model on iterator data.
- Parameters
iterator (Iterator) – iterator containing batch samples of data.
- Returns
the performance and metrics of the training session.
- Return type
dict
-
abstract
run(iterator, criterion, optimizer, *args, **kwargs)[source]¶ Train one time the model on iterator data.
- Parameters
iterator (Iterator) – iterator containing batch samples of data.
criterion (Loss) – loss function to measure scores.
optimizer (Optimizer) – optimizer used during training to update weights.
- Returns
the performance and metrics of the training session.
- Return type
dict
-
save(filename=None, name=None, dirpath='.', checkpoint=True)[source]¶ Save the best torch model.
- Parameters
name (str, optional) – name of the model. The default is “model.pt”.
dirpath (str, optional) – path to the desired foldre location. The default is “.”.
checkpoint (bool, optional) – True to save the model at the best checkpoint during training.
sentarget.nn.models.lstm¶
The Bilinear Long Short Term Memory is a vanilla model used for targeted sentiment analysis, and compared to more elaborated models.
Example:
# Defines the shape of the models
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 128
OUTPUT_DIM = len(LABEL.vocab)
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.25
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = BiLSTM(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
-
class
sentarget.nn.models.lstm.BiLSTM(input_dim, embedding_dim=100, hidden_dim=128, output_dim=7, n_layers=2, bidirectional=True, dropout=0.25, pad_idx_text=1, unk_idx_text=0, pad_idx_label=0, embeddings=None)[source]¶ This bilinear model uses the sklearn template, i.e. with a fit method within the module.
Make sure to add a criterion and optimizer when loading a model.
input_dim(int): input dimension, i.e. dimension of the incoming words.embedding_dim(int): dimension of the word embeddigns.hidden_dim(int): dimmension used to map words with the recurrent unit.output_dim(int): dimension used for classification. This one should be equals to the number of classes.n_layers(int): number of recurrent layers.bidirectional(bool): if True, set two recurrent layers in the opposite direction.dropout(float): ratio of connections set to zeros.pad_idx_text(int): index of the <pad> text token.pad_idx_label(int): index of the <pad> label token.embeddings(torch.Tensor): pretrained embeddings, of shape(input_dim, embeddings_dim).
Examples:
>>> INPUT_DIM = len(TEXT.vocab) >>> EMBEDDING_DIM = 100 >>> HIDDEN_DIM = 128 >>> OUTPUT_DIM = len(LABEL.vocab) >>> N_LAYERS = 2 >>> BIDIRECTIONAL = True >>> DROPOUT = 0.25 >>> PAD_IDX_TEXT = TEXT.vocab.stoi[TEXT.pad_token] >>> PAD_IDX_LABEL = LABEL.vocab.stoi[LABEL.unk_token] >>> model = BiLSTM(INPUT_DIM, ... EMBEDDING_DIM, ... HIDDEN_DIM, ... OUTPUT_DIM, ... N_LAYERS, ... BIDIRECTIONAL, ... DROPOUT, ... pad_idx_text=PAD_IDX_TEXT, ... pad_idx_label=PAD_IDX_LABEL) >>> criterion = nn.CrossEntropyLoss() >>> optimizer = metrics.Adam(model.parameters()) >>> model.fit(50, train_data, eval_data, criterion, optimizer)
-
evaluate(iterator, criterion, optimizer, verbose=True)[source]¶ Evaluate one time the model on iterator data.
- Parameters
iterator (Iterator) – iterator containing batch samples of data.
criterion (Loss) – loss function to measure scores.
optimizer (Optimizer) – optimizer used during training to update weights.
verbose (bool) – if True display a progress bar.
- Returns
the performance and metrics of the training session.
- Return type
dict
-
forward(text, length)[source]¶ One forward step.
Note
The forward propagation requires text’s length, so a padded pack can be applied to batches.
- Parameters
text (torch.tensor) – text composed of word embeddings vectors from one batch.
length (torch.tensor) – vector indexing the lengths of text.
Examples:
>>> for batch in data_iterator: >>> text, length = batch.text >>> model.forward(text, length)
-
get_accuracy(y_tilde, y)[source]¶ Computes the accuracy from a set of predictions and gold labels.
Note
The resulting accuracy does not count <pad> tokens.
- Parameters
y_tilde (torch.tensor) – predictions.
y (torch.tensor) – gold labels.
- Returns
the global accuracy, of shape 0.
- Return type
torch.tensor
-
init_embeddings(embeddings, ignore_index=None)[source]¶ Initialize the embeddings vectors from pre-trained embeddings vectors.
Warning
By default, the embeddings will set to zero the tokens at indices 0 and 1, that should corresponds to <pad> and <unk>.
Examples:
>>> # TEXT: field used to extract text, sentences etc. >>> PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] >>> UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token] >>> pretrained_embeddings = TEXT.vocab.vectors >>> model.init_embeddings(pretrained_embeddings, ignore_index=[PAD_IDX, UNK_IDX])
- Parameters
embeddings (torch.tensor) – pre-trained word embeddings, of shape
(input_dim, embedding_dim).ignore_index (int or iterable) – if not None, set to zeros tensors at the indices provided.
-
run(iterator, criterion, optimizer, verbose=True)[source]¶ Train one time the model on iterator data.
- Parameters
iterator (Iterator) – iterator containing batch samples of data.
criterion (Loss) – loss function to measure scores.
optimizer (Optimizer) – optimizer used during training to update weights.
verbose (bool) – if True display a progress bar.
- Returns
the performance and metrics of the training session.
- Return type
dict
sentarget.nn.models.gru¶
The Bilinear Recurrent network is a vanilla model used for targeted sentiment analysis, and compared to more elaborated models.
Example:
# Defines the shape of the models
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 128
OUTPUT_DIM = len(LABEL.vocab)
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.25
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = BiGRU(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
-
class
sentarget.nn.models.gru.BiGRU(input_dim, embedding_dim=100, hidden_dim=128, output_dim=7, n_layers=2, bidirectional=True, dropout=0.25, pad_idx_text=1, unk_idx_text=0, pad_idx_label=0, embeddings=None)[source]¶ This bilinear model uses the sklearn template, i.e. with a fit method within the module.
Make sure to add a criterion and optimizer when loading a model.
input_dim(int): input dimension, i.e. dimension of the incoming words.embedding_dim(int): dimension of the word embeddigns.hidden_dim(int): dimmension used to map words with the recurrent unit.output_dim(int): dimension used for classification. This one should be equals to the number of classes.n_layers(int): number of recurrent layers.bidirectional(bool): if True, set two recurrent layers in the opposite direction.dropout(float): ratio of connections set to zeros.pad_idx_text(int): index of the <pad> text token.pad_idx_label(int): index of the <pad> label token.embeddings(torch.Tensor): pretrained embeddings, of shape(input_dim, embeddings_dim).
Examples:
>>> INPUT_DIM = len(TEXT.vocab) >>> EMBEDDING_DIM = 100 >>> HIDDEN_DIM = 128 >>> OUTPUT_DIM = len(LABEL.vocab) >>> N_LAYERS = 2 >>> BIDIRECTIONAL = True >>> DROPOUT = 0.25 >>> PAD_IDX_TEXT = TEXT.vocab.stoi[TEXT.pad_token] >>> PAD_IDX_LABEL = LABEL.vocab.stoi[LABEL.unk_token] >>> model = BiGRU(INPUT_DIM, ... EMBEDDING_DIM, ... HIDDEN_DIM, ... OUTPUT_DIM, ... N_LAYERS, ... BIDIRECTIONAL, ... DROPOUT, ... pad_idx_text=PAD_IDX_TEXT, ... pad_idx_label=PAD_IDX_LABEL) >>> criterion = nn.CrossEntropyLoss() >>> optimizer = metrics.Adam(model.parameters()) >>> model.fit(50, train_data, eval_data, criterion, optimizer)
-
evaluate(iterator, criterion, optimizer, verbose=True)[source]¶ Evaluate one time the model on iterator data.
- Parameters
iterator (Iterator) – iterator containing batch samples of data.
criterion (Loss) – loss function to measure scores.
optimizer (Optimizer) – optimizer used during training to update weights.
verbose (bool) – if True display a progress bar.
- Returns
the performance and metrics of the training session.
- Return type
dict
-
forward(text, length)[source]¶ One forward step.
Note
The forward propagation requires text’s length, so a padded pack can be applied to batches.
- Parameters
text (torch.tensor) – text composed of word embeddings vectors from one batch.
length (torch.tensor) – vector indexing the lengths of text.
Examples:
>>> for batch in data_iterator: >>> text, length = batch.text >>> model.forward(text, length)
-
get_accuracy(y_tilde, y)[source]¶ Computes the accuracy from a set of predictions and gold labels.
Note
The resulting accuracy does not count <pad> tokens.
- Parameters
y_tilde (torch.tensor) – predictions.
y (torch.tensor) – gold labels.
- Returns
the global accuracy, of shape 0.
- Return type
torch.tensor
-
init_embeddings(embeddings, ignore_index=None)[source]¶ Initialize the embeddings vectors from pre-trained embeddings vectors.
Warning
By default, the embeddings will set to zero the tokens at indices 0 and 1, that should corresponds to <pad> and <unk>.
Examples:
>>> # TEXT: field used to extract text, sentences etc. >>> PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] >>> UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token] >>> pretrained_embeddings = TEXT.vocab.vectors >>> model.init_embeddings(pretrained_embeddings, ignore_index=[PAD_IDX, UNK_IDX])
- Parameters
embeddings (torch.tensor) – pre-trained word embeddings, of shape
(input_dim, embedding_dim).ignore_index (int or iterable) – if not None, set to zeros tensors at the indices provided.
-
run(iterator, criterion, optimizer, verbose=True)[source]¶ Train one time the model on iterator data.
- Parameters
iterator (Iterator) – iterator containing batch samples of data.
criterion (Loss) – loss function to measure scores.
optimizer (Optimizer) – optimizer used during training to update weights.
verbose (bool) – if True display a progress bar.
- Returns
the performance and metrics of the training session.
- Return type
dict
sentarget.metrics¶
sentarget.metrics.confusion¶
Defines a `ConfusionMatrix`, used to compute scores (True Positive, False Negative etc.).
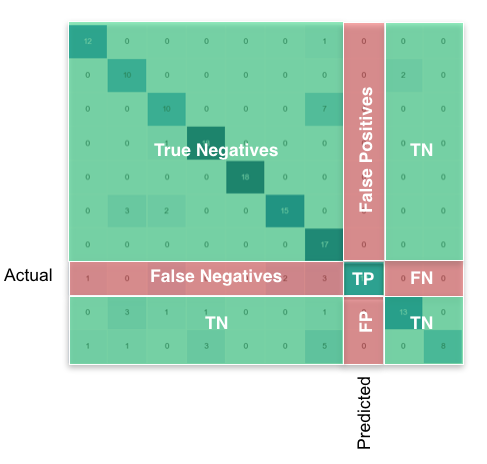
Example:
# Create a confusion matrix and ignore the labels
# associated to <unk> and <pad>.
confusion = ConfusionMatrix(num_classes=10, unk_idx=0, pad_idx=1)
# Update the confusion matrix with a list of predictions and labels
confusion.update(gold_labels, predictions)
# Get the global accuracy, precision, scores from attributes or methods
confusion.accuracy()
-
class
sentarget.metrics.confusion.ConfusionMatrix(labels=None, data=None, names=None, axis_label=0, axis_pred=1)[source]¶ A
`ConfusionMatrix`is a matrix of shape \((C, C)\), used to index predictions \(p \in C\) regarding their gold labels (or truth labels).-
flatten(*args, **kwargs)[source]¶ Flatten a confusion matrix to retrieve its prediction and gold labels.
-
normalize()[source]¶ Nomalize the confusion
matrix.\[\text{Norm}(Confusion) = \frac{Confusion}{sum(Confusion)}\]Note
The operation is not inplace, and thus does not modify the attribute
`matrix`.- Returns
normalized confusion matrix.
- Return type
numpy.ndarray
-
plot(names=None, normalize=False, cmap='Blues', cbar=True)[source]¶ Plot the
matrixin a new figure.Note
plot is compatible with matplotlib 3.1.1. If you are using an older version, the display may change (version < 3.0).
- Parameters
labels (list) – list of ordered names corresponding to the indices used as gold labels.
normalize (bool) – if
Truenormalize thematrix.cmap (string or matplotlib.pyplot.cmap) – heat map colors.
cbar (bool) – if
True, display the colorbar associated to the heat map plot.
- Returns
axes corresponding to the plot.
- Return type
matplotlib.Axes
-
to_dataframe(names=None, normalize=False)[source]¶ Convert the
ConfusionMatrixto a DataFrame.- Parameters
names (list) – list containing the ordered names of the indices used as gold labels.
normalize (bool) – if
True, normalize thematrix.
- Returns
pandas.DataFrame
-
to_dict()[source]¶ Convert the
ConfusionMatrixto a dict.global accuracy(float): accuracy obtained on all classes.sensitivity(float): sensitivity obtained on all classes.precision(float): precision obtained on all classes.specificity(float): specificity obtained on all classes.confusion(list): confusion matrix obtained on all classes.
- Returns
dict
-
sentarget.metrics.functional¶
Elementary functions used for statistical reports.
-
sentarget.metrics.functional.accuracy(matrix)[source]¶ Per class accuracy from a confusion matrix.
\[ACC(M) = \frac{TP(M) + TN(M)}{TP(M) + TN(M) + FP(M) + FN(M)}\]- Parameters
matrix (numpy.ndarray) – confusion matrix of shape \((C, C)\).
- Returns
numpy.ndarray
-
sentarget.metrics.functional.false_discovery_rate(matrix)[source]¶ False discovery rate from a confusion matrix.
\[FDR(M) = \frac{FP(M)}{FP(M) + TP(M)}\]- Parameters
matrix (numpy.ndarray) – confusion matrix of shape \((C, C)\).
- Returns
numpy.ndarray
-
sentarget.metrics.functional.false_negative(matrix)[source]¶ False negatives values from a confusion matrix.
\[FN(M) = \sum_{j=0}^{C-1}{M_j} - \text{Diag}(M)\]- Parameters
matrix (numpy.ndarray) – confusion matrix of shape \((C, C)\).
- Returns
numpy.ndarray
-
sentarget.metrics.functional.false_negative_rate(matrix)[source]¶ False negative rate from a confusion matrix.
\[FNR(M) = \frac{FN(M)}{FN(M) + TP(M)}\]- Parameters
matrix (numpy.ndarray) – confusion matrix of shape \((C, C)\).
- Returns
numpy.ndarray
-
sentarget.metrics.functional.false_positive(matrix)[source]¶ False positives values from a confusion matrix.
\[FP(M) = \sum_{i=0}^{C-1}{M_i} - \text{Diag}(M)\]- Parameters
matrix (numpy.ndarray) – confusion matrix of shape \((C, C)\).
- Returns
numpy.ndarray
-
sentarget.metrics.functional.false_positive_rate(matrix)[source]¶ False positive rate from a confusion matrix.
\[FPR(M) = \frac{FP(M)}{FP(M) + FN(M)}\]- Parameters
matrix (numpy.ndarray) – confusion matrix of shape \((C, C)\).
- Returns
numpy.ndarray
-
sentarget.metrics.functional.flatten_matrix(matrix, axis_label=0, axis_pred=1, map=None)[source]¶ Flatten a confusion matrix to retrieve its prediction and gold labels.
- Parameters
matrix (numpy.ndarray) – confusion matrix of shape \((C, C)\).
axis_label (int) – axis index corresponding to the gold labels.
axis_pred (int) – axis index corresponding to the predictions.
map (dict) – dictionary to map indices to label.
- Returns
gold labels and predictions.
-
sentarget.metrics.functional.negative_predictive_value(matrix)[source]¶ Negative predictive value from a confusion matrix.
\[NPV(M) = \frac{TN(M)}{TN(M) + FN(M)}\]- Parameters
matrix (numpy.ndarray) – confusion matrix of shape \((C, C)\).
- Returns
numpy.ndarray
-
sentarget.metrics.functional.positive_predictive_value(matrix)[source]¶ Positive predictive value from a confusion matrix.
\[PPV(M) = \frac{TP(M)}{TP(M) + FP(M)}\]- Parameters
matrix (numpy.ndarray) – confusion matrix of shape \((C, C)\).
- Returns
numpy.ndarray
-
sentarget.metrics.functional.true_negative(matrix)[source]¶ True negatives values from a confusion matrix.
\[TN(M) = \sum_{i=0}^{C-1}{\sum_{j=0}^{C-1}{M_{i, j}}} - FN(M) + FP(M) + TP(M)\]- Parameters
matrix (numpy.ndarray) – confusion matrix of shape \((C, C)\).
- Returns
numpy.ndarray
-
sentarget.metrics.functional.true_negative_rate(matrix)[source]¶ True negative rate from a confusion matrix.
\[TNR(M) = \frac{TN(M)}{TN(M) + FP(M)}\]- Parameters
matrix (numpy.ndarray) – confusion matrix of shape \((C, C)\).
- Returns
numpy.ndarray
sentarget.tuner¶
sentarget.tuner.tuner¶
Hyperparameters optimization using a grid search algorithm.
Basically, you need to provide a set of parameters that will be modified.
The grid search will run on all permutations from the set of parameters provided.
Usually, you modify the hyperparameters and models’ modules (ex, dropout etc.).
In addition, if you are using custom losses or optimizer that needs additional arguments / parameters,
you can provide them through the specific dictionaries (see the documentation of Tuner).
Examples:
# Hyper parameters to tune
params_hyper = {
'epochs': [150],
'lr': np.arange(0.001, 0.3, 0.01).tolist(), # Make sure to convert it to a list (for saving after)
}
# Parameters affecting the models
params_model = {
'model': [BiLSTM]
'hidden_dim': [100, 150, 200, 250], # Model attribute
'n_layers': [1, 2, 3], # Model attribute
'bidirectional': [False, True], # Model attribute
'LSTM.dropout': [0.2, 0.3, 0.4, 0.6], # Modify all LSTM dropout
# ...
}
params_loss = {
'criterion': [CrossEntropyLoss]
}
params_optim = {
'criterion': [Adam]
}
tuner = Tuner(params_hyper, params_loss=params_loss, params_optim=params_optim)
# Grid Search
tuner.fit(train_iterator, eval_iterator, verbose=True)
-
class
sentarget.tuner.tuner.Tuner(params_hyper=None, params_model=None, params_loss=None, params_optim=None, options=None)[source]¶ The
Tunerclass is used for hyper parameters tuning. From a set of models and parameters to tune, this class will look at the best model’s performance.Note
To facilitate the search and hyperameters tuning, it is recommended to use the
sentarget.nn.models.Modelabstract class as parent class for all of your models.hyper_params(dict): dictionary of hyperparameters to tune.performance(dict): dictionary of all models’ performances.
-
fit(train_data, eval_data, verbose=True, saves=False, **kwargs)[source]¶ Run the hyper parameters tuning.
- Parameters
train_data (iterator) – training dataset.
eval_data (iterator) – dev dataset.
verbose (bool) – if
True, display a statistical log at each search.saves (bool) – if
Truesaves all trained models.dirsaves (string) – path to the saving directory.
Examples:
>>> from sentarget.metrics import Tuner >>> from sentarget.nn.models.lstm import BiLSTM >>> from sentarget.nn.models.gru import BiGRU >>> # Hyper parameters to tune >>> tuner = Tuner( ... params_hyper={ ... 'epochs': [2, 3], ... 'lr': [0.01], ... 'vectors': 'model.txt' ... } ... params_model={ ... 'model': [BiLSTM], ... } ... params_loss={ ... 'criterion': [torch.nn.CrossEntropyLoss], ... 'ignore_index': 0 ... } ... params_optim={ ... 'optimizer': [torch.optim.Adam] ... } ... ) >>> # train_iterator = torchtext data iterato >>> tuner.fit(train_iterator, valid_iterator)
-
log_conf(config_hyper={}, config_model={}, config_loss={}, config_optim={}, *args, **kwargs)[source]¶ Generate a configuration log from the generated set of configurations files.
- Parameters
config_hyper (dict) – hyper parameters configuration file.
config_model (dict) – model parameters configuration file.
config_loss (dict) – loss parameters configuration file.
config_optim (dict) – optimizer parameters configuration file.
- Returns
configuration file representation.
- Return type
string
-
log_init(hyper, model, loss, optim)[source]¶ Generate a general configuration log.
- Parameters
hyper (int) – number of hyper parameters permutations.
model (int) – number of model parameters permutations.
loss (int) – number of loss parameters permutations.
optim (int) – number of optimizer parameters permutations.
- Returns
general log.
- Return type
string
sentarget.tuner.functional¶
Optimization functions used for hyperparameters tuning.
-
sentarget.tuner.functional.init_cls(class_instance, config)[source]¶ Initialize a class instance from a set of possible values.
Note
More parameters can be added than the object need. They will just not be used.
- Parameters
class_instance (class) – class to initialize.
config (dict) – possible values of init parameters.
- Returns
initialized object
-
sentarget.tuner.functional.tune(model, config)[source]¶ Note
If the key is separated with a ‘.’, it means the first index is the module to change, then the attribute
key = 'LSTM.dropout'will modify only the dropout corresponding toLSTMlayersThe double underscore
__is used to modify a specific attribute by its name (and not its type), likekey = 'linear__in_features'will modify only thein_featuresattribute from theLinearlayer saved under the attributelinearof the custom model.Warning
The operation modify the model inplace.
- Parameters
model (Model) – the model to tune its hyperparameters.
config (dict) – dictionary of parameters to change.
- Returns
the configuration to apply to a model.
- Return type
dict
Examples:
>>> from sentarget.nn.models.lstm import BiLSTM >>> # Defines the shape of the models >>> INPUT_DIM = len(TEXT.vocab) >>> EMBEDDING_DIM = 100 >>> HIDDEN_DIM = 128 >>> OUTPUT_DIM = len(LABEL.vocab) >>> N_LAYERS = 2 >>> BIDIRECTIONAL = True >>> DROPOUT = 0.25 >>> PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] >>> model = BiLSTM(INPUT_DIM, ... EMBEDDING_DIM, ... HIDDEN_DIM, ... OUTPUT_DIM, ... N_LAYERS, ... BIDIRECTIONAL, ... DROPOUT, ... PAD_IDX) >>> config = {'LSTM.dropout': 0.2} >>> tune(model, config)
sentarget.datasets¶
sentarget.datasets.norecfine¶
The NoReCfine class defines the latest datasets used for targeted sentiment analysis.
# First, download the training / dev / test data
train_data, dev_data, test_data = NoReCfine.splits(train_data="path_to_train",
dev_data="path_to_eval",
test_data="path_to_test")
sentarget.datasets.nonlpl¶
NoNLPL is a dataset instance used to load pre-trained embeddings.
-
class
sentarget.datasets.nonlpl.NoNLPL(filepath)[source]¶ The Norwegian Bokmal NLPL dataset contains more than 1,000,000 pre-trained word embeddings from the norwegian language.
Examples:
>>> vectors = NoNLPL.load()
sentarget.utils¶
sentarget.utils.functions¶
Utility functions.
-
sentarget.utils.functions.append2dict(main_dict, *dicts)[source]¶ Append key values to another dict with the same keys.
- Parameters
main_dict (dict) – dictionary where values will be added.
*dicts (dict) – dictionaries to extract values and append to another one. These dictionaries should have the same keys as dict.
Examples:
>>> dict1 = {"key1": [], "key2": []} >>> dict2 = {"key1": 0, "key2": 1} >>> append2dict(dict1, dict2) >>> dict1 {"key1": [0], "key2": [1]} >>> dict3 = {"key1": 2, "key2": 3} >>> dict4 = {"key1": 4, "key2": 5} >>> append2dict(dict1, dict3, dict4) >>> dict1 {"key1": [0, 2, 4], "key2": [1, 3, 5]}
-
sentarget.utils.functions.permutation_dict(params)[source]¶ Generate a list of configuration files used to tune a model.
- Returns
list
Examples:
>>> hyper_params = {'dropout': [0, 0.1, 0.2, 0.3], ... 'in_features': [10, 20, 30, 40], ... 'out_features': [20, 30, 40, 50]} >>> permutation_dict(hyper_params) [{'dropout': 0, 'in_features': 10, 'out_features': 20}, {'dropout': 0, 'in_features': 10, 'out_features': 30}, {'dropout': 0, 'in_features': 10, 'out_features': 40}, {'dropout': 0, 'in_features': 10, 'out_features': 50}, {'dropout': 0, 'in_features': 20, 'out_features': 20}, {'dropout': 0, 'in_features': 20, 'out_features': 30}, ... ]
-
sentarget.utils.functions.rgetattr(obj, attr, *args)[source]¶ Get an attribute recursively.
- Parameters
obj (object) – object to get the attribute.
attr (string) – path to the attribute.
*args –
- Returns
attribute
-
sentarget.utils.functions.rsetattr(obj, attr, val)[source]¶ Set an attribute recursively.
..note
Attributes should be split with a dot ``.``.
- Parameters
obj (object) – object to set the attribute.
attr (string) – path to the attribute.
val (value) – value to set.
-
sentarget.utils.functions.serialize_dict(data)[source]¶ Serialize recursively a dict to another dict composed of basic python object (list, dict, int, float, str…)
- Parameters
data (dict) – dict to serialize
- Returns
dict
Examples:
>>> data = {'tensor': torch.tensor([0, 1, 2, 3, 4]), ... 'sub_tensor': [torch.tensor([1, 2, 3, 4, 5])], ... 'data': [1, 2, 3, 4, 5], ... 'num': 1} >>> serialize_dict(data) {'tensor': None, 'sub_tensor': [], 'data': [1, 2, 3, 4, 5], 'num': 1}
-
sentarget.utils.functions.serialize_list(data)[source]¶ Serialize recursively a list to another list composed of basic python object (list, dict, int, float, str…)
- Parameters
data (list) – list to serialize
- Returns
list
Examples:
>>> data = [1, 2, 3, 4] >>> serialize_list(data) [1, 2, 3, 4] >>> data = [torch.tensor([1, 2, 3, 4])] >>> serialize_list(data) [] >>> data = [1, 2, 3, 4, torch.tensor([1, 2, 3, 4])] >>> serialize_list(data) [1, 2, 3, 4]
sentarget.utils.display¶
This module defines basic function to render a simulation, like progress bar and statistics table.
-
sentarget.utils.display.describe_dict(state_dict, key_length=50, show_iter=False, capitalize=False, pad=False, sep_key=', ', sep_val='=')[source]¶ Describe and render a dictionary. Usually, this function is called on a
Solverstate dictionary, and merged with a progress bar.- Parameters
state_dict (dict) – the dictionary to showcase.
key_length (int) – number of letter from a string name to show.
show_iter (bool) – if
True, show iterable. Note that this may destroy the rendering.capitalize (bool) – if
Truewill capitalize the keys.pad (bool) – if
True, will pad the displayed number up to 4 characters.sep_key (string) – key separator.
sep_val (string) – value separator.
- Returns
the dictionary to render.
- Return type
string
-
sentarget.utils.display.get_time(start_time, end_time)[source]¶ Get ellapsed time in minutes and seconds.
- Parameters
start_time (float) – strarting time
end_time (float) – ending time
- Returns
elapsed time in minutes elapsed_secs (float): elapsed time in seconds.
- Return type
elapsed_mins (float)
-
sentarget.utils.display.progress_bar(current_index, max_index, prefix=None, suffix=None, start_time=None)[source]¶ Display a progress bar and duration.
- Parameters
current_index (int) – current state index (or epoch number).
max_index (int) – maximal numbers of state.
prefix (str, optional) – prefix of the progress bar. The default is None.
suffix (str, optional) – suffix of the progress bar. The default is None.
start_time (float, optional) – starting time of the progress bar. If not None, it will display the time spent from the beginning to the current state. The default is None.
- Returns
None. Display the progress bar in the console.
sentarget.utils.decorator¶
This module defines decorators for functions and methods.
-
sentarget.utils.decorator.deprecated(reason)[source]¶ Deprecated decorator.
This is a decorator which can be used to mark functions as deprecated. It will result in a warning being emitted when the function is used. 
